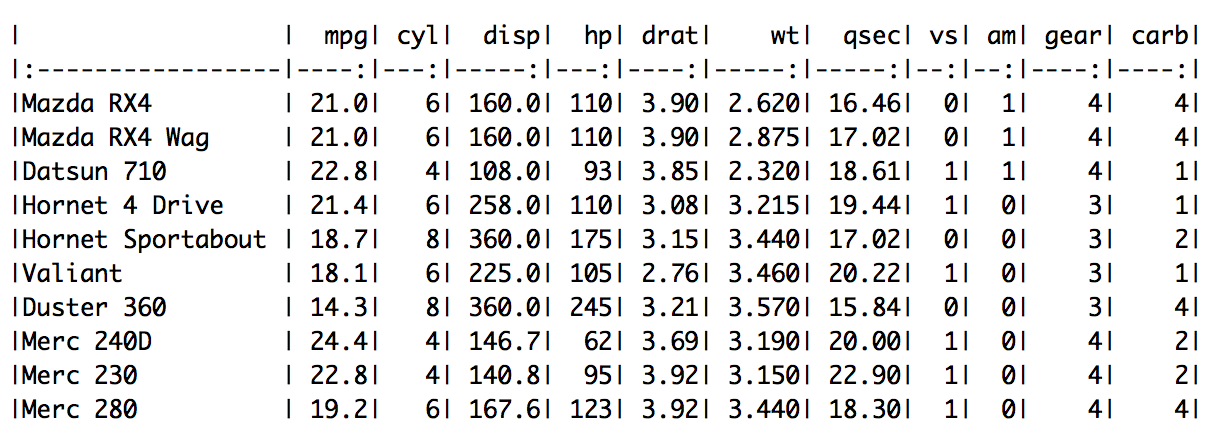
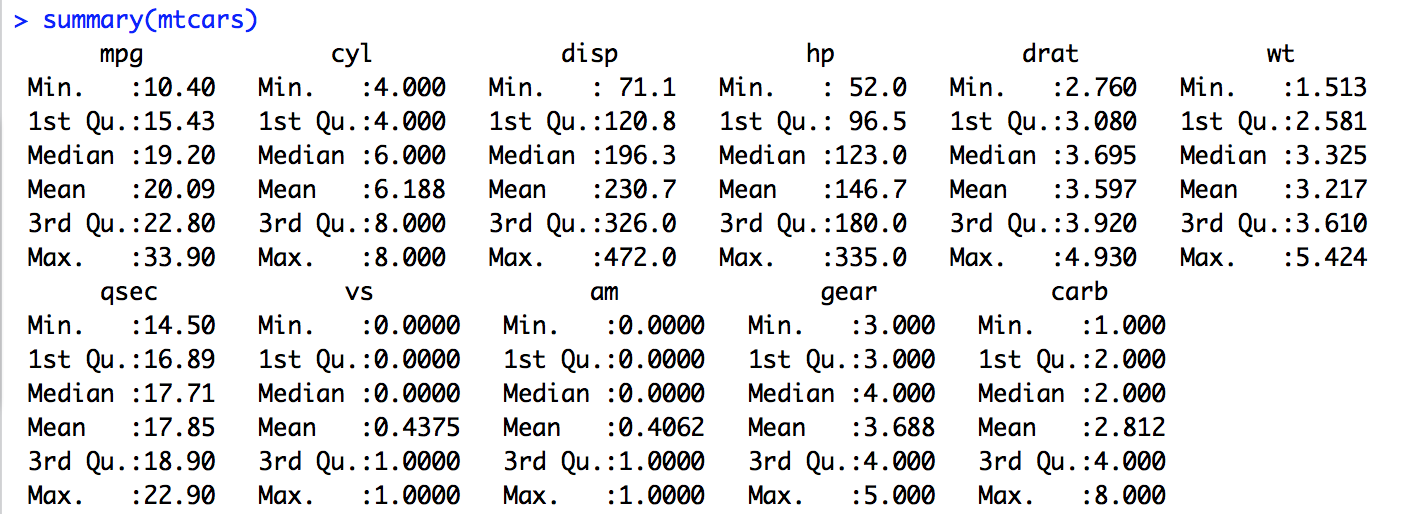
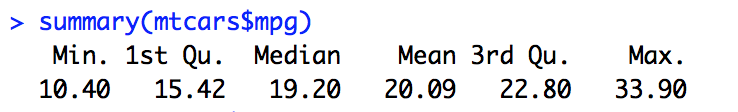We concluded our previous attempt to predict the onset of diabetes with a few questions. Lets try to answer the questions in this post.
The model that we built previously had an accuracy of 77.73% - with a caveat that we used the same data for training the model and do the prediction. And we had a few questions.
Is there a better model to predict? If so, how do we build and measure it?
Yes. There can be many models that we can build on the data set. Lets try to build one more and try to measure it.
Are there any disadvantages in building the model and testing the model on the same data set?
Certainly, its like looking at the questions that ll be asked before taking an examination. Any average person can memorize the answers and can increase the chance of scoring better marks in the exam. Same is the case with the model that we build. It stands a better chance and accuracy if we work on the same data set to predict.
Lets try to build a decision tree (without going through the math behind them) on the data set . We ll use the model to make prediction (as we did earlier). We ll also measure the accuracy of the model.
Here we ll build a Decision Tree using Recursive Partitioning to classify the data. The technique is to classify members of the population by splitting it into sub-populations based on several dichotomous independent variables. The process is termed recursive because each sub-population may in turn be split an indefinite number of times until the splitting process terminates after a particular stopping criterion is reached.
A major advantage with this method is this is very simple and more intuitive.
rpart.fit <- rpart(Outcome ~ .,data=pimaimpute)
prp(rpart.fit, faclen = 0, box.palette = "auto", branch.type = 5, cex = 1)
Doing that produces this beautiful Decision Tree.

The model splits the data set into two sections based on Glucose Level and then on Age (for the section where Glucose level is <128) and on BMI and so on until it finds stopping criteria.
As we have build the model, lets use this model for predict (on the same data set).
rpart.pred <- predict(rpart.fit, data=pimaimpute, type = "class")
Lets predict the accuracy of this model.



Read More
Recap
The model that we built previously had an accuracy of 77.73% - with a caveat that we used the same data for training the model and do the prediction. And we had a few questions.
Is there a better model to predict? If so, how do we build and measure it?
Yes. There can be many models that we can build on the data set. Lets try to build one more and try to measure it.
Are there any disadvantages in building the model and testing the model on the same data set?
Certainly, its like looking at the questions that ll be asked before taking an examination. Any average person can memorize the answers and can increase the chance of scoring better marks in the exam. Same is the case with the model that we build. It stands a better chance and accuracy if we work on the same data set to predict.
A different model - Decision Trees
Lets try to build a decision tree (without going through the math behind them) on the data set . We ll use the model to make prediction (as we did earlier). We ll also measure the accuracy of the model.
Here we ll build a Decision Tree using Recursive Partitioning to classify the data. The technique is to classify members of the population by splitting it into sub-populations based on several dichotomous independent variables. The process is termed recursive because each sub-population may in turn be split an indefinite number of times until the splitting process terminates after a particular stopping criterion is reached.
A major advantage with this method is this is very simple and more intuitive.
rpart.fit <- rpart(Outcome ~ .,data=pimaimpute)
prp(rpart.fit, faclen = 0, box.palette = "auto", branch.type = 5, cex = 1)
Doing that produces this beautiful Decision Tree.

How to read this?
The model splits the data set into two sections based on Glucose Level and then on Age (for the section where Glucose level is <128) and on BMI and so on until it finds stopping criteria.
As we have build the model, lets use this model for predict (on the same data set).
rpart.pred <- predict(rpart.fit, data=pimaimpute, type = "class")
Lets predict the accuracy of this model.


Confusion Matrix Visualized

Closing Notes
This model has got an accuracy of 83.98% (versus our Linear Model's accuracy of 77.73%).
One important question that we ll address in the next post is -
Are there any disadvantages in building the model and testing the model on the same data set?
P.S.: The complete code that was used for this article is here.